Discovering fully semantic representations via centroid- and orientation-aware feature learning
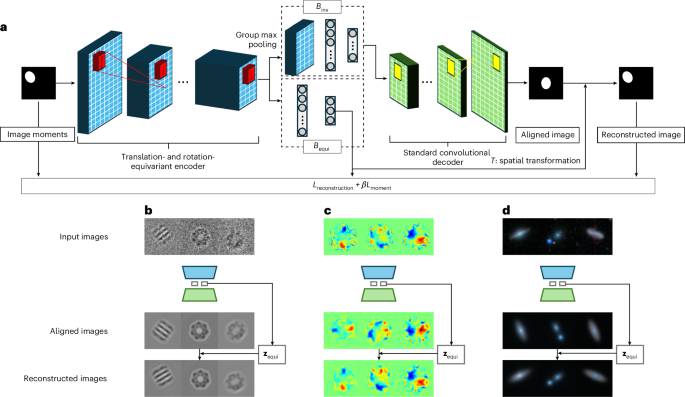
CODAE architecture Translation- and rotation-equivariant encoder CODAE uses a translation- and rotation-equivariant encoder, denoted by Eϕ, that utilizes group-equivariant convolutional layers. These layers apply convolutions with stacks of rotated kernels at equally spaced orientations, enabling the encoder to capture both translational and rotational equivariance in a manner that is analogous to the continuous operation described … Read more